
Die Kursrallye der Tesla-Aktie in den vergangenen Tagen wurde durch eine Kaufempfehlung von Morgan Stanley angeheizt. Die Analystenfirma sieht den zusätzlichen Wert des Tesla-eigenen Chip-Designs und des neuen Supercomputers bei bis zu 500 Milliarden Dollar. In nur wenigen Stunden stieg der Marktwert des Unternehmens um 80 Milliarden Dollar. Hier zuerst mal eine Analyse auf Bloomberg Television (in Englisch):
Doch die Frage ist, was genau macht Teslas Dojo Supercomputer und das Chip-Design so wertvoll? Und dazu müssen wir verstehen, wie neuronale Netzwerke als Rückgrad von künstlicher Intelligenz – und damit von Teslas Full Self Driving (FSD) – genau funktioniert.
Kochbuch Versus Künstliche Intelligenz
Ich möchte mit einem Vergleich zu Erstellung und der Verwendung eines Kochbuchs beginnen. Wenn wir ein Kochbuch schreiben wollen, dann kaufen wir die Zutaten, suchen alte Rezepte von Oma und Mama raus, stellen sicher, dass wir einen Herd, Backofen, Mixer und andere Koch- und Backutensilien haben und beginnen die Speisen zu kochen und zu backen. Wir kochen und backen dasselbe Rezept so oft, bis wir das perfekte Rezept haben. Zum Abschluss machen wir ein Appetit anregendes Foto von der fertigen Köstlichkeit und schreiben das endgültige Rezept für das Kochbuch nieder.
Unser Endprodukt ist dann ein Kochbuch und das ist es, was wir dann verkaufen. Unsere Leser kaufen dann nur das Kochbuch, aber sie erhalten dazu keinerlei Zutaten oder gar fertiges Essen mit. Das müssen sie schon selber machen.

Eine KI – zum Beispiel ein großes Sprachmodell (auf Englisch: Large Language Model oder abgekürzt LLM) oder das FSD KI-Modell , das auf den Tesla runtergeladen wird – wird mit Daten trainiert, und zwar mit Milliarden von Bildern, hunderten Milliarden von Textseiten, oder eben zig Millionen Stunden von Videos von Autofahrten. Dabei wird das neuronale Netzwerk, das aus wenigen bis hin zu Millionen von Knoten bestehen kann, und in dem Matrizenrechnung – also Umwandlungen des Inputs von mehreren anderen Knoten – durchgeführt und Parameter gespeichert werden.
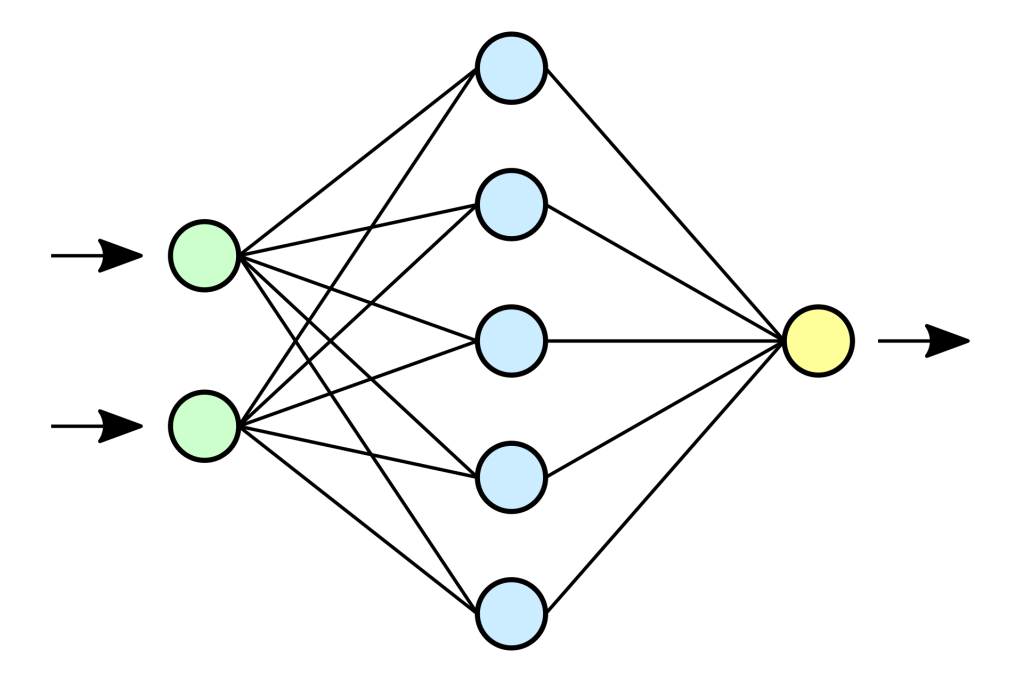
Mit nachfolgenden Feineinstellungen und Nachverbesserungen wird das Modell dann perfektioniert und korrigiert. So wie bei einem Rezept die Zutaten und Backzeiten verändert und angepasst werden.
Solch ein KI-Modell mit den gespeicherten Parametern (=Kochbuch mit Rezepten) kann dann heruntergeladen, aber es kommt ohne die Videos, Bildern oder Texte, wie auch ein Kochbuch ohne die Zutaten oder fertigen Speisen kommt.
Verbesserung des KI-Modells
Wie sich herausstellt, funktionieren die im Allgemeinen KI-Modelle besser, mit je mehr Daten sie trainiert werden. Vor GPT-4 gab es GPT-1/2/3/3.5, und jedes hatte mehr Trainingsdaten und die Nachbesserungen und Feineinstellungen wurden immer raffinierter.
Tesla kann theoretisch auf mittlerweile mehr als fünf Millionen ausgelieferte Autos zurückgreifen, die das Hardware-Kit für autonomes Fahren eingebaut haben, und die Daten – sofern es von den Besitzern erlaubt wurde – holen und den eigenen Supercomputer damit trainieren. Schon 2017 bemerkte ein Benutzer, dass Tesla pro Monat in etwa 1,8 Gigabyte pro Monat von seinem Tesla herunterlädt.
Superküche Versus Supercomputer
Nathan Myhrvold, ehemaliger CTO von Microsoft, investierte vor einigen Jahren mehrere Millionen (angeblich jenseits von 10 Millionen) Dollar in eine “Superküche” und stattete sie unter anderem mit Geräten aus, die man normalerweise nur in Chemielabors findet, wie zum Beispiel einen Vakuumdestillator. Er began mit Modernist Cuisine eine Serie von Kochbüchern zu schaffen, die ihresgleichen suchen. Nicht nur die Fotos sind wie aus einer anderen Welt, auch die Rezepte. Ein Rezept für Pommes Frites in der Vakuumkammer benötigt 48 Stunden, um zu den perfekten Pommes zu gelangen. Auch lud er dazu eine Reihe von Top-Chefs aus aller Welt ein, um sein Projekt zu verwirklichen.
Die Top-Chefs, also die Top-KI-Experten, sind heute bei den großen amerikanischen Firmen beschäftigt. Und auch sie haben Zugang zu den besten Chip-Clustern, um ihre KI-Modelle zu erstellen Je größer (und damit hoffentlich auch besser) das Modell werden soll, um so besser muss die Küchenausstattung, also die Computing Hardware sein. Und je mehr Rezepte man haben will und je besser die sein sollen, desto mehr Öfen und Herde brauchen sie, um entsprechend viele Varianten ausprobieren zu können. Und ähnlich ist es bei KI-Modellen. Wir brauchen die entsprechende Computing Power, gerade bei der Verarbeitung von Milliarden von Bildern und zig Millionen Stunden an Videos.
Nun verwendet man hier bei KI vor allem GPUs und TPUs. Wir kennen sicherlich CPUs (Central Processing Units). Die stecken in allen PCs drin, oft mit dem Intel Logo. Doch für diese vielen Parallelberechnungen, wie sie KIs brauchen (wir reden hier von Millionen von Knoten, in denen Matrixberechnungen durchgeführt werden) eignen sich GPUs (Graphical Processing Units) besser. Nvidia hatte diese ursprünglich für die Graphikdarstellungen auf ihren Graphikkarten entwickelt, nun stellt sich heraus, dass sie sich hervorragend sowohl für KIs als auch für Perzeptionssysteme, wie sie autonome Autos haben, eignen. Deren Kameras, Lidars, oder Radars nehmen viel graphische und Vektordaten auf, die massiv parallel berechnet werden müssen. TPUs (Tensor Processing Units) wiederum gehen noch einen Schritt weiter und sind noch spezifischer auf die Matrizenrechnungen von KI-Modellen konditioniert.

Also so, wie ein Herd gut für Schnitzelbacken ist, aber nicht gut für Kuchenbacken, so sind CPUs zwar gute für Skalarmultiplikationen, aber nicht für die massiven Parallelrechnungen.
Mit dem Tesla Supercomputer, der aus 10.000 Stück von Nvidias H100 GPUs besteht (jedes Stück kostet aktuell übrigens 30.000 Dollar), kann Tesla sehr viel rascher die Modelle für die FSD erstellen, feintunen und nachbessern und die daraus resultierenden Modelle mit den Parametern rascher wieder auf die Autos aufspielen. Modelle als Mehrzahl deshalb, weil es tatsächlich mehrere Modelle sind. So hat Tesla auch u.a. das Deep Rain-Modell, das Korrekturberechungen zu den Regentropfen, die wie Linsen auf den Kameras wirken und das Bild verzerren, durchführt und damit sicherstellt, dass ein Tesla auch bei Regen sicher den Durchblick hat kann.
Die Änderungen mit der FSD 12
Es gibt auch einen Unterschied im Ansatz, wie Tesla bislang an die FSD rangegangen ist und wie sie jetzt mit der FSD 12 das System trainiert haben. Und dazu können wir das mit anderen Beispielen vergleichen, bei denen ein ähnlicher Paradigmenwechsel stattgefunden hat.
Übersetzungswerkzeuge wie Google Translate wurden bis vor einigen Jahren vor allem von Linguisten trainiert. Die gaben unter anderem genaue Grammatikregeln vor oder welche Worte positive oder negative Konnotationen haben. Ein sehr komplexes Regelwerk entstand dabei, und zwischen den Sprachen mussten dazu die entsprechenden Verbindungen hergestellt werden. Aber man stieß an Grenzen, weil sich die Übersetzungen nur langsam und immer weniger verbesserten und mit jeder neuen Sprache der Aufwand wuchs.
Als man dann 2016 ein neuronales Netzwerk dahinterlegte konnte Google nicht nur die Anzahl der Codezeilen um den Faktor 1.000 verringern (von 500.000 auf 500), sondern auch die Ergebnisse massiv verbessern. Denn anstatt dem System Regeln vorzugeben suchte sich die KI nun diese aus den Trainingsdaten selbst heraus und erstellt Wahrscheinlichkeitsgraphen.
Genauso passiert es bei den aktuell so viel Interesse findenden generativen KIs. So kommt in den Milliarden von Textzeilen ein Satz wie „Die Katze sitzt auf …“ sicherlich mehrmals vor und kann mit Tisch/Baum/Fensterbrett/Flugzeugflügel/Dampfstrahl ergänzt werden. Aber nicht alle sind gleich wahrscheinlich. Manche mehr, manche gar nicht.
Ähnlich ging Deepmind von Google übrigens auch bei AlphaGo, AlphaGo Zero und AlphaZero vor. AlphaGo wurden die Regeln beigebracht und mit 30 Millionen von Menschen gespielten Partien trainiert. AlphaGo Zero wurde nicht mehr mit Spielen trainiert, nur die Regeln beigebracht und hat es dann gegen sich selbst spielen lassen. AlphaGo Zero gewann mit 100:0 gegen AlphaGo (AlphaGo hatte 2016 den koreanischen Go-Weltmeister Lee Sedol mit 4:1 besiegt). AlphaZero wurde weder mit Spielen trainiert, noch wurde ihm das (gesamte) Regelwerk gesagt. Damit konnte es u.a. Go und Schach spielen. Und es gewann gegen AlphaGo Zero mit 60:40.
Den bisherigen Versionen der FSD wurden die Regeln vorgegeben. „Stopp bei Rot“, „Biege ab, wenn kein Auto/Fußgänger/Hund/Ente/Baustellenhütchen da ist“ und so weiter. In der Version 12 ging Tesla aber davon ab und ließ das System aus den Videodaten – die von den Millionen von Teslas aus aller Welt stammen – die Regeln selbst ableiten. Elon Musk wies in seiner Demo der FSD 12 mehrmals darauf hin.
Natürlich muss Tesla dieses Modell auch feintunen und nachbessern, aber Tesla muss nicht vorher dem System all die Regeln mühsam beibringen.
Auswirkung
Mit dem eigenen Supercomputer kann Tesla somit eine ganze Menge an Teilproblemen schneller anpacken. Also beispielsweise nicht nur das autonome Fahren selbst (das schon komplex genug ist), sondern zum Beispiel auch das Korrekturberechnen von Kameradaten im Regen (Deep Rain). Man kann das Modell spezifisch auf bestimmte Sachen trainieren (Hunde, Rollstuhlfahrer, Tunnelfahrten, spezielle Licht-Schatten-Verhältnisse, seltene Objekte auf der Straße).
Damit lässt sich die FSD 12 vermutlich auch rascher auf andere Fahrzeugtypen migrieren. Vom Model 3 auf Semi Truck, der ein ganz anderes Gewicht, Fahrverhalten oder Kameraposition aufweist. Und womöglich auch anderen Herstellern die FSD auf deren Autos aufspielen lassen. Dazu gab es bereits erste Meldungen. Oder, warum nicht, auf einen Tesla Bot?
Es ist somit leicht erkannbar, dass sich daraus neue Erlöspotenziale für Tesla erschließen lassen. Die Inhouse-Kompetenz zu KI, die Entwicklung eines eigenen KI-Chips, der in Millionen von Teslas bereits eingebaut ist und dessen Verwendung, wie auch die von Nvidia Chips in einen Tesla Dojo mit zukünftig wohl zigtausenden Prozessoren macht Tesla zu einem KI-Powerhouse. Und das bringt vielleicht einen Hinweis auf die zukünftigen Potenziale, die sich für Tesla eröffnen und deren Investoren.
Hinweis zu mehr KI-Wissen
Diese und ähnliche Aufschlüsselungen zu (generativer) künstlicher Intelligenz bringe ich in meinem bereits zweiten, im November 2023 erscheinenden Buch zu KI. Kreative Intelligenz: Wie ChatGPT und Co. die Welt verändern werden. Es kann bereits vorbestellt werden.

KREATIVE INTELLIGENZ
Über ChatGPT hat man viel gelesen in der letzten Zeit: die künstliche Intelligenz, die ganze Bücher schreiben kann und der bereits jetzt unterstellt wird, Legionen von Autoren, Textern und Übersetzern arbeitslos zu machen. Und ChatGPT ist nicht allein, die KI-Familie wächst beständig. So malt DALL-E Bilder, Face Generator simuliert Gesichter und MusicLM komponiert Musik. Was erleben wir da? Das Ende der Zivilisation oder den Beginn von etwas völlig Neuem? Zukunftsforscher Dr. Mario Herger ordnet die neuesten Entwicklungen aus dem Silicon Valley ein und zeigt auf, welche teils bahnbrechenden Veränderungen unmittelbar vor der Tür stehen.
Dieser Beitrag ist auch auf Englisch erschienen.

„we make sure“ = „wir stellen sicher“. Nicht „machen sicher“. Weia!
LikeLike
Danke! Habe ich korrigiert!
So ist das eben, wenn man schon zu lange in den USA lebt.
LikeLike
Ich bin hier über die Behauptung stark irritiert, im „Dojo“ genannten Supercomputer würden NVIDIA GPUs verwendet, wenn Elon höchstselbst doch mehrfach deutlich ausgedrückt hat, dass das auf NVIDIA basierende System und das auf Teslas eigener Chipentwicklung basierende „Dojo“ genannte System zwei völlig verschiedene Dinge sind:
„We’ll actually take NVIDIA hardware as fast as NVIDIA will deliver it to us. And frankly, I don’t know if they could deliver us enough GPUs, we might not need Dojo, but they can’t.“
LikeLike
Hier: https://www.notebookcheck.com/Tesla-wird-Milliarden-in-Nvidia-und-AMD-Hardware-investieren-um-seine-KI-Aktivitaeten-voranzutreiben.797961.0.html
LikeLike